How and why machine learning and AI can enhance financial analysis
Gerd Altmann
Proxy servers can be used not only by IT-developers, they are also useful in the financial industry, namely in financial sentiment analysis. Let me explain.
In finance, data is ever so important: it provides insight and helps to make better decisions. Financial data is all around us, so the most successful companies are those which
know how to gather it, and
know how to interpret it.
An important subset is sentiment data — information on how people perceive the given product, event, idea, etc. The fundamental categories here are “perceive positively” and “perceive negatively”.
Until recently, sentiment data wasn’t quantifiable: It was impossible to measure people’s sentiments precisely. With the advent of natural language processing and machine learning, however, this task has finally become attainable.
In this article, we’ll explore how you can utilize sentiment analysis and web scraping to make better financial decisions.
Overview of sentiment analysis
Even the best industry professionals cannot keep up with all the latest news, reports, updates, and rumors. This data often drives the decision to, say, buy or sell the given company’s stock. Here’s a typical example:
Amid growing concerns about COVID-19, the government of Country X decides to use video conferencing instead of holding in-person meetings.
Video Conferencing Software Y is one of the most popular video conferencing solutions on the market, so the markets are expecting Software Y to acquire a plethora of new users.
Software Y’s rise in popularity is reflected in its stock price.
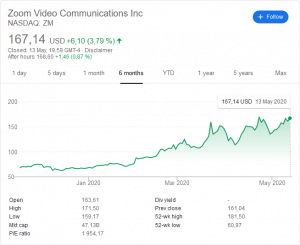
The scenario above borrows heavily from Zoom’s recent success, which can be illustrated by the following chart:
investing.com
To a certain degree, the process of analyzing this data — news, reports, updates, and rumors — can be automated
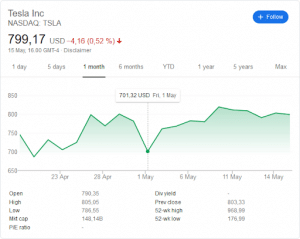
Tesla's stock jumped 2.5% after Tencent said it amassed a 5% stake in the electric car maker. Ocwen jumped 12% premarket after disclosing it reached a deal with New York regulators that will end third-party monitoring of its business within the next three weeks. In addition, restrictions on buying mortgage-servicing rights may get eased. Cara Therapeutics's shares surged 16% premarket, after the biotech company reported positive results in a trial of a treatment for uremic pruritus.
Another great example is the recent tweet of Elon Musk: “Tesla stock price is too high imo”.
This has decreased Tesla’s stock price. Notice the dip on the 1st of May:
investing.com
The system that makes sentiment analysis possible is called natural language processing (or NLP for short.) As their name suggests, NLP algorithms are designed to analyze the meaning behind texts in natural (i.e. human-made: English or Chinese) languages.
Although building and implementing an NLP system takes a lot of resources, the benefits make this endeavor worthwhile:'
The algorithm boasts superior reaction time: it executes commands in mere milliseconds and works 24/7.
It also offers scalability: Its “expertise” can be applied to — given enough computing resources — every source of financial data.
How does sentiment analysis work?
Every text has a certain attitude, either positive, negative, or neutral. Sentiment analysis aims to determine the attitude of the given text (in most cases, of individual phrases and sentences) via splitting it into individual words (called tokens), determining their attitude, and then determining the overall attitude of the target text.
This principle may seem confusing, so let’s play around with this technology ourselves.
Python programming language has an NLP-focused library called NLTK (Natural Language Toolkit). This website features an interactive implementation of NLTK’s sentiment analysis algorithm. Try inputting different sentences to see how the algorithm perceives them.
Let’s test the following sentences:
“This project is a great tool for processing raw data.”The algorithm determines that this text is positive.
“This project will change the tech landscape.” The algorithm determines that this text is neutral.
“This project failed to live up to its potential.” The algorithm determines that this text is negative.
Shortcomings of sentiment analysis algorithms
Previously, we used sentences with rather straightforward meanings in the interactive prompt: Words like “great” and “fail” usually mark the entire context. What about something more complex? Let’s try it out.
Let's take this phrase as an example: “The automobile industry has seen better days.” The algorithm determines that this text is neutral.
These examples show that traditional NLP algorithms have a hard time parsing implicit meanings:
Nuanced phrases,
Idioms,
Metaphors, etc.
Enhancing sentiment analysis with machine learning
This is where machine learning comes to rescue: We can train an ML algorithm on countless examples to make it “understand” the text’s context. Here’s a blueprint for such a project:
Collect a dataset that focuses on financial sentiment texts.
Mark up each text’s sentiment.
Build a sentiment analysis model that is optimized for “financial language”.
The basis for a machine learning algorithm lies in huge volumes of data to train on: In our case, the algorithm would analyze news headlines and social media captions to try and see the correlations between texts and the meanings behind them. Given enough training material, the algorithm can “learn” (hence the name, machine learning) about the context around the given text.
David Wallach, the creator of various financial data scrapers, echoes the shortcomings of traditional (non-deep learning) algorithms:
One main objective of this project is to classify the sentiment of companies based on verified user’s tweets as well as articles published by reputable sources. Using current (free) text based sentiment analysis packages such as nltk, textblob, and others, I was unable to achieve decent sentiment analysis with regards to investing.
For example, a tweet would say Amazon is a buy, you must invest now and these libraries would classify it as negative or neutral sentiment. This is due to the training sets these classifiers were built on. For this reason, I decided to write a script (scripts/classify.py) that takes in the json representation of the database downloaded from the Firebase console (using export to JSON option) and lets you manually classify each sentence.
We now see the importance of data in the sentiment analysis workflow. But how can we acquire it?
Overview of web scraping
In the term “sentiment analysis”, the “analysis” part refers to understanding the data — and the NLP algorithms we’ve explored earlier in the article can do just that. Web scraping, on the other hand, allows us to actually obtain the data to analyze.
Vladimir Fomenko, founder & CEO of Infatica.io
This term refers to the process of extracting and organizing data from websites.
How does web scraping work?
Web scraping is possible thanks to the way that websites organize data. Each website element — text, link, image, dynamic functionality, and so on — belongs to its respective category, denoted by standardized HTML tags.
A web scraper can navigate these elements with ease, locating and saving the data you need to gather.
For example, Stocker, software for scraping financial data, follows the processes we outlined above:
It generates google queries, grabbing the latest articles that focus on a particular company.
Then, it parses the articles for information, trying to detect whether important pieces of information are positive or negative.
We can also use sentiment analysis in other areas:
Credit score analysis. Software product called LenddoScore can process the data available about the applicant online: This may include their social media profiles, browsing behavior, browsing history, and other markers. The software then rates the borrower’s creditworthiness.
Contracts analysis. JP Morgan has implemented a plethora of machine learning algorithms for numerous tasks. The company tested an NLP algorithm designed for contract analysis — and it has managed to save 360,000 man-hours in a year.
Customer service. Chatbots, the trendiest technology of the last few years, are powered by NLP algorithms. Financial institutions often pride themselves in offering great customer experience — and scaling their support via chatbots is a great way to do it.
Using proxies to ensure that your analysis runs successfully
Most websites don’t allow web scraping for various reasons. Here’s a typical example: a price aggregator tries to collect price data from multiple e-commerce businesses. Once this data is published on the aggregator website, potential customers will see that Vendor M offers the best price. To prevent this, other vendors may restrict scraping their websites whatsoever.
Upon receiving a request to their website, they try to detect whether it comes from a genuine user or from a web scraping bot. While the genuine user gets a pass, the bot gets blocked.
However, it is possible to circumvent these anti-bot systems: using proxies, you can make your scrapers appear as real users.
Out of all the numerous proxy types, residential proxies are the optimal solution: as their name suggests, they allow your scraper to appear as a real user, a resident of the country you selected. This enables you to bypass anti-scraping systems.
Conclusion
Every trader decides which type of analysis to use and which trading techniques to implement. But to my mind, improving financial sentiment analysis with AI and proxy servers is the new word in trading.
Vladimir Fomenko is the founder & CEO of Infatica.io, a global peer-to-business proxy network
Proxy servers can be used not only by IT-developers, they are also useful in the financial industry, namely in financial sentiment analysis. Let me explain.
In finance, data is ever so important: it provides insight and helps to make better decisions. Financial data is all around us, so the most successful companies are those which
know how to gather it, and
know how to interpret it.
An important subset is sentiment data — information on how people perceive the given product, event, idea, etc. The fundamental categories here are “perceive positively” and “perceive negatively”.
Until recently, sentiment data wasn’t quantifiable: It was impossible to measure people’s sentiments precisely. With the advent of natural language processing and machine learning, however, this task has finally become attainable.
In this article, we’ll explore how you can utilize sentiment analysis and web scraping to make better financial decisions.
Overview of sentiment analysis
Even the best industry professionals cannot keep up with all the latest news, reports, updates, and rumors. This data often drives the decision to, say, buy or sell the given company’s stock. Here’s a typical example:
Amid growing concerns about COVID-19, the government of Country X decides to use video conferencing instead of holding in-person meetings.
Video Conferencing Software Y is one of the most popular video conferencing solutions on the market, so the markets are expecting Software Y to acquire a plethora of new users.
Software Y’s rise in popularity is reflected in its stock price.
The scenario above borrows heavily from Zoom’s recent success, which can be illustrated by the following chart:
investing.com
To a certain degree, the process of analyzing this data — news, reports, updates, and rumors — can be automated
Tesla's stock jumped 2.5% after Tencent said it amassed a 5% stake in the electric car maker. Ocwen jumped 12% premarket after disclosing it reached a deal with New York regulators that will end third-party monitoring of its business within the next three weeks. In addition, restrictions on buying mortgage-servicing rights may get eased. Cara Therapeutics's shares surged 16% premarket, after the biotech company reported positive results in a trial of a treatment for uremic pruritus.
Another great example is the recent tweet of Elon Musk: “Tesla stock price is too high imo”.
This has decreased Tesla’s stock price. Notice the dip on the 1st of May:
investing.com
The system that makes sentiment analysis possible is called natural language processing (or NLP for short.) As their name suggests, NLP algorithms are designed to analyze the meaning behind texts in natural (i.e. human-made: English or Chinese) languages.
Although building and implementing an NLP system takes a lot of resources, the benefits make this endeavor worthwhile:'
The algorithm boasts superior reaction time: it executes commands in mere milliseconds and works 24/7.
It also offers scalability: Its “expertise” can be applied to — given enough computing resources — every source of financial data.
How does sentiment analysis work?
Every text has a certain attitude, either positive, negative, or neutral. Sentiment analysis aims to determine the attitude of the given text (in most cases, of individual phrases and sentences) via splitting it into individual words (called tokens), determining their attitude, and then determining the overall attitude of the target text.
This principle may seem confusing, so let’s play around with this technology ourselves.
Python programming language has an NLP-focused library called NLTK (Natural Language Toolkit). This website features an interactive implementation of NLTK’s sentiment analysis algorithm. Try inputting different sentences to see how the algorithm perceives them.
Let’s test the following sentences:
“This project is a great tool for processing raw data.”The algorithm determines that this text is positive.
“This project will change the tech landscape.” The algorithm determines that this text is neutral.
“This project failed to live up to its potential.” The algorithm determines that this text is negative.
Shortcomings of sentiment analysis algorithms
Previously, we used sentences with rather straightforward meanings in the interactive prompt: Words like “great” and “fail” usually mark the entire context. What about something more complex? Let’s try it out.
Let's take this phrase as an example: “The automobile industry has seen better days.” The algorithm determines that this text is neutral.
These examples show that traditional NLP algorithms have a hard time parsing implicit meanings:
Nuanced phrases,
Idioms,
Metaphors, etc.
Enhancing sentiment analysis with machine learning
This is where machine learning comes to rescue: We can train an ML algorithm on countless examples to make it “understand” the text’s context. Here’s a blueprint for such a project:
Collect a dataset that focuses on financial sentiment texts.
Mark up each text’s sentiment.
Build a sentiment analysis model that is optimized for “financial language”.
The basis for a machine learning algorithm lies in huge volumes of data to train on: In our case, the algorithm would analyze news headlines and social media captions to try and see the correlations between texts and the meanings behind them. Given enough training material, the algorithm can “learn” (hence the name, machine learning) about the context around the given text.
David Wallach, the creator of various financial data scrapers, echoes the shortcomings of traditional (non-deep learning) algorithms:
One main objective of this project is to classify the sentiment of companies based on verified user’s tweets as well as articles published by reputable sources. Using current (free) text based sentiment analysis packages such as nltk, textblob, and others, I was unable to achieve decent sentiment analysis with regards to investing.
For example, a tweet would say Amazon is a buy, you must invest now and these libraries would classify it as negative or neutral sentiment. This is due to the training sets these classifiers were built on. For this reason, I decided to write a script (scripts/classify.py) that takes in the json representation of the database downloaded from the Firebase console (using export to JSON option) and lets you manually classify each sentence.
We now see the importance of data in the sentiment analysis workflow. But how can we acquire it?
Overview of web scraping
In the term “sentiment analysis”, the “analysis” part refers to understanding the data — and the NLP algorithms we’ve explored earlier in the article can do just that. Web scraping, on the other hand, allows us to actually obtain the data to analyze.
Vladimir Fomenko, founder & CEO of Infatica.io
This term refers to the process of extracting and organizing data from websites.
How does web scraping work?
Web scraping is possible thanks to the way that websites organize data. Each website element — text, link, image, dynamic functionality, and so on — belongs to its respective category, denoted by standardized HTML tags.
A web scraper can navigate these elements with ease, locating and saving the data you need to gather.
For example, Stocker, software for scraping financial data, follows the processes we outlined above:
It generates google queries, grabbing the latest articles that focus on a particular company.
Then, it parses the articles for information, trying to detect whether important pieces of information are positive or negative.
We can also use sentiment analysis in other areas:
Credit score analysis. Software product called LenddoScore can process the data available about the applicant online: This may include their social media profiles, browsing behavior, browsing history, and other markers. The software then rates the borrower’s creditworthiness.
Contracts analysis. JP Morgan has implemented a plethora of machine learning algorithms for numerous tasks. The company tested an NLP algorithm designed for contract analysis — and it has managed to save 360,000 man-hours in a year.
Customer service. Chatbots, the trendiest technology of the last few years, are powered by NLP algorithms. Financial institutions often pride themselves in offering great customer experience — and scaling their support via chatbots is a great way to do it.
Using proxies to ensure that your analysis runs successfully
Most websites don’t allow web scraping for various reasons. Here’s a typical example: a price aggregator tries to collect price data from multiple e-commerce businesses. Once this data is published on the aggregator website, potential customers will see that Vendor M offers the best price. To prevent this, other vendors may restrict scraping their websites whatsoever.
Upon receiving a request to their website, they try to detect whether it comes from a genuine user or from a web scraping bot. While the genuine user gets a pass, the bot gets blocked.
However, it is possible to circumvent these anti-bot systems: using proxies, you can make your scrapers appear as real users.
Out of all the numerous proxy types, residential proxies are the optimal solution: as their name suggests, they allow your scraper to appear as a real user, a resident of the country you selected. This enables you to bypass anti-scraping systems.
Conclusion
Every trader decides which type of analysis to use and which trading techniques to implement. But to my mind, improving financial sentiment analysis with AI and proxy servers is the new word in trading.
Vladimir Fomenko is the founder & CEO of Infatica.io, a global peer-to-business proxy network
Xryma Means "Money" in Greek. Its Euronext Paris Debut Won't Raise Any
Featured Videos
Fintech Education Explained: How Finance Magnates Academy Helps You Build a Career
Fintech Education Explained: How Finance Magnates Academy Helps You Build a Career
Fintech Education Explained: How Finance Magnates Academy Helps You Build a Career
Fintech Education Explained: How Finance Magnates Academy Helps You Build a Career
What does it take to build a successful career in fintech?
In this exclusive interview, Dora Christofi, Head of Marketing at Finance Magnates, sits down with Jeff Patterson, Head of Education at Finance Magnates Academy, to discuss why fintech education has become more important than ever.
They explore how Finance Magnates Academy is helping students, professionals, career changers, HR teams, and fintech companies build practical industry knowledge through expert-led courses and recognised certifications.
In this interview:
✅ Why fintech needs specialised education
✅ The difference between theory and practical learning
✅ How Finance Magnates Academy prepares professionals for real careers
✅ The value of industry-recognised certifications
✅ How companies can improve employee onboarding and training
✅ What's coming next for Finance Magnates Academy
Whether you're looking to start a career in fintech, grow within the financial services industry, or improve your team's onboarding process, this conversation offers valuable insights from one of the industry's leading education initiatives.
Learn more about Finance Magnates Academy:
👉 https://academy.financemagnates.com
About Finance Magnates Academy
Finance Magnates Academy provides practical fintech education through expert-led courses, professional certifications, and corporate training. Designed for individuals and organisations, the Academy helps professionals build real-world skills across brokerage operations, trading, compliance, payments, financial markets, and fintech.
Connect with Finance Magnates
🌐 Website: https://www.financemagnates.com
🔗 LinkedIn: https://www.linkedin.com/company/finance-magnates
📺 Subscribe for more interviews, market insights, and fintech education.
#Fintech #FintechEducation #FinanceMagnates #FintechCareers #FinancialServices #CorporateTraining #OnlineLearning #FintechTraining
What does it take to build a successful career in fintech?
In this exclusive interview, Dora Christofi, Head of Marketing at Finance Magnates, sits down with Jeff Patterson, Head of Education at Finance Magnates Academy, to discuss why fintech education has become more important than ever.
They explore how Finance Magnates Academy is helping students, professionals, career changers, HR teams, and fintech companies build practical industry knowledge through expert-led courses and recognised certifications.
In this interview:
✅ Why fintech needs specialised education
✅ The difference between theory and practical learning
✅ How Finance Magnates Academy prepares professionals for real careers
✅ The value of industry-recognised certifications
✅ How companies can improve employee onboarding and training
✅ What's coming next for Finance Magnates Academy
Whether you're looking to start a career in fintech, grow within the financial services industry, or improve your team's onboarding process, this conversation offers valuable insights from one of the industry's leading education initiatives.
Learn more about Finance Magnates Academy:
👉 https://academy.financemagnates.com
About Finance Magnates Academy
Finance Magnates Academy provides practical fintech education through expert-led courses, professional certifications, and corporate training. Designed for individuals and organisations, the Academy helps professionals build real-world skills across brokerage operations, trading, compliance, payments, financial markets, and fintech.
Connect with Finance Magnates
🌐 Website: https://www.financemagnates.com
🔗 LinkedIn: https://www.linkedin.com/company/finance-magnates
📺 Subscribe for more interviews, market insights, and fintech education.
#Fintech #FintechEducation #FinanceMagnates #FintechCareers #FinancialServices #CorporateTraining #OnlineLearning #FintechTraining
What does it take to build a successful career in fintech?
In this exclusive interview, Dora Christofi, Head of Marketing at Finance Magnates, sits down with Jeff Patterson, Head of Education at Finance Magnates Academy, to discuss why fintech education has become more important than ever.
They explore how Finance Magnates Academy is helping students, professionals, career changers, HR teams, and fintech companies build practical industry knowledge through expert-led courses and recognised certifications.
In this interview:
✅ Why fintech needs specialised education
✅ The difference between theory and practical learning
✅ How Finance Magnates Academy prepares professionals for real careers
✅ The value of industry-recognised certifications
✅ How companies can improve employee onboarding and training
✅ What's coming next for Finance Magnates Academy
Whether you're looking to start a career in fintech, grow within the financial services industry, or improve your team's onboarding process, this conversation offers valuable insights from one of the industry's leading education initiatives.
Learn more about Finance Magnates Academy:
👉 https://academy.financemagnates.com
About Finance Magnates Academy
Finance Magnates Academy provides practical fintech education through expert-led courses, professional certifications, and corporate training. Designed for individuals and organisations, the Academy helps professionals build real-world skills across brokerage operations, trading, compliance, payments, financial markets, and fintech.
Connect with Finance Magnates
🌐 Website: https://www.financemagnates.com
🔗 LinkedIn: https://www.linkedin.com/company/finance-magnates
📺 Subscribe for more interviews, market insights, and fintech education.
#Fintech #FintechEducation #FinanceMagnates #FintechCareers #FinancialServices #CorporateTraining #OnlineLearning #FintechTraining
What does it take to build a successful career in fintech?
In this exclusive interview, Dora Christofi, Head of Marketing at Finance Magnates, sits down with Jeff Patterson, Head of Education at Finance Magnates Academy, to discuss why fintech education has become more important than ever.
They explore how Finance Magnates Academy is helping students, professionals, career changers, HR teams, and fintech companies build practical industry knowledge through expert-led courses and recognised certifications.
In this interview:
✅ Why fintech needs specialised education
✅ The difference between theory and practical learning
✅ How Finance Magnates Academy prepares professionals for real careers
✅ The value of industry-recognised certifications
✅ How companies can improve employee onboarding and training
✅ What's coming next for Finance Magnates Academy
Whether you're looking to start a career in fintech, grow within the financial services industry, or improve your team's onboarding process, this conversation offers valuable insights from one of the industry's leading education initiatives.
Learn more about Finance Magnates Academy:
👉 https://academy.financemagnates.com
About Finance Magnates Academy
Finance Magnates Academy provides practical fintech education through expert-led courses, professional certifications, and corporate training. Designed for individuals and organisations, the Academy helps professionals build real-world skills across brokerage operations, trading, compliance, payments, financial markets, and fintech.
Connect with Finance Magnates
🌐 Website: https://www.financemagnates.com
🔗 LinkedIn: https://www.linkedin.com/company/finance-magnates
📺 Subscribe for more interviews, market insights, and fintech education.
#Fintech #FintechEducation #FinanceMagnates #FintechCareers #FinancialServices #CorporateTraining #OnlineLearning #FintechTraining
The FX & CFD Market Is Changing Fast. Here's What's Coming Next (2026)
The FX & CFD Market Is Changing Fast. Here's What's Coming Next (2026)
The FX & CFD Market Is Changing Fast. Here's What's Coming Next (2026)
The FX & CFD Market Is Changing Fast. Here's What's Coming Next (2026)
The FX & CFD Market Is Changing Fast. Here's What's Coming Next (2026)
The FX & CFD Market Is Changing Fast. Here's What's Coming Next (2026)
Where is the FX & CFD industry really heading in 2026?
In this free Finance Magnates Intelligence masterclass, industry experts explore the latest data shaping the global FX & CFD market, how regulation and regional demand influence expansion planning, and how brokerages benchmark performance across 265 firms on the FM Intelligence Portal.
In this session you'll learn:
✔ Where the FX/CFD industry is heading in H2 2026
✔ Why compliance should guide regional expansion decisions
✔ How internal performance compares when benchmarked against 265 brokers
✔ Regional demand shifts across Europe, APAC, and LATAM
✔Broker volume rankings, verification, and FM Intelligence Portal data
Speakers:
• Ramzi Ahmad, Director of Intelligence, Finance Magnates
• Sylwester Majewski, Head of Insights & Reporting Hub, Finance Magnates
• Philios Petrides, Data & Business Intelligence Consultant
If you work in brokerage, fintech, compliance, business development or market strategy, this session offers practical insights backed by verified industry data.
Access the FM Intelligence Portal at: https://datalab.financemagnates.com/
🔔 Subscribe to Finance Magnates for more webinars, interviews and market intelligence covering the global online trading industry.
#FinanceMagnates #FX #CFD #Fintech #Trading #Brokerage #MarketIntelligence #RegTech #Compliance #Forex
Where is the FX & CFD industry really heading in 2026?
In this free Finance Magnates Intelligence masterclass, industry experts explore the latest data shaping the global FX & CFD market, how regulation and regional demand influence expansion planning, and how brokerages benchmark performance across 265 firms on the FM Intelligence Portal.
In this session you'll learn:
✔ Where the FX/CFD industry is heading in H2 2026
✔ Why compliance should guide regional expansion decisions
✔ How internal performance compares when benchmarked against 265 brokers
✔ Regional demand shifts across Europe, APAC, and LATAM
✔Broker volume rankings, verification, and FM Intelligence Portal data
Speakers:
• Ramzi Ahmad, Director of Intelligence, Finance Magnates
• Sylwester Majewski, Head of Insights & Reporting Hub, Finance Magnates
• Philios Petrides, Data & Business Intelligence Consultant
If you work in brokerage, fintech, compliance, business development or market strategy, this session offers practical insights backed by verified industry data.
Access the FM Intelligence Portal at: https://datalab.financemagnates.com/
🔔 Subscribe to Finance Magnates for more webinars, interviews and market intelligence covering the global online trading industry.
#FinanceMagnates #FX #CFD #Fintech #Trading #Brokerage #MarketIntelligence #RegTech #Compliance #Forex
Where is the FX & CFD industry really heading in 2026?
In this free Finance Magnates Intelligence masterclass, industry experts explore the latest data shaping the global FX & CFD market, how regulation and regional demand influence expansion planning, and how brokerages benchmark performance across 265 firms on the FM Intelligence Portal.
In this session you'll learn:
✔ Where the FX/CFD industry is heading in H2 2026
✔ Why compliance should guide regional expansion decisions
✔ How internal performance compares when benchmarked against 265 brokers
✔ Regional demand shifts across Europe, APAC, and LATAM
✔Broker volume rankings, verification, and FM Intelligence Portal data
Speakers:
• Ramzi Ahmad, Director of Intelligence, Finance Magnates
• Sylwester Majewski, Head of Insights & Reporting Hub, Finance Magnates
• Philios Petrides, Data & Business Intelligence Consultant
If you work in brokerage, fintech, compliance, business development or market strategy, this session offers practical insights backed by verified industry data.
Access the FM Intelligence Portal at: https://datalab.financemagnates.com/
🔔 Subscribe to Finance Magnates for more webinars, interviews and market intelligence covering the global online trading industry.
#FinanceMagnates #FX #CFD #Fintech #Trading #Brokerage #MarketIntelligence #RegTech #Compliance #Forex
Where is the FX & CFD industry really heading in 2026?
In this free Finance Magnates Intelligence masterclass, industry experts explore the latest data shaping the global FX & CFD market, how regulation and regional demand influence expansion planning, and how brokerages benchmark performance across 265 firms on the FM Intelligence Portal.
In this session you'll learn:
✔ Where the FX/CFD industry is heading in H2 2026
✔ Why compliance should guide regional expansion decisions
✔ How internal performance compares when benchmarked against 265 brokers
✔ Regional demand shifts across Europe, APAC, and LATAM
✔Broker volume rankings, verification, and FM Intelligence Portal data
Speakers:
• Ramzi Ahmad, Director of Intelligence, Finance Magnates
• Sylwester Majewski, Head of Insights & Reporting Hub, Finance Magnates
• Philios Petrides, Data & Business Intelligence Consultant
If you work in brokerage, fintech, compliance, business development or market strategy, this session offers practical insights backed by verified industry data.
Access the FM Intelligence Portal at: https://datalab.financemagnates.com/
🔔 Subscribe to Finance Magnates for more webinars, interviews and market intelligence covering the global online trading industry.
#FinanceMagnates #FX #CFD #Fintech #Trading #Brokerage #MarketIntelligence #RegTech #Compliance #Forex
Where is the FX & CFD industry really heading in 2026?
In this free Finance Magnates Intelligence masterclass, industry experts explore the latest data shaping the global FX & CFD market, how regulation and regional demand influence expansion planning, and how brokerages benchmark performance across 265 firms on the FM Intelligence Portal.
In this session you'll learn:
✔ Where the FX/CFD industry is heading in H2 2026
✔ Why compliance should guide regional expansion decisions
✔ How internal performance compares when benchmarked against 265 brokers
✔ Regional demand shifts across Europe, APAC, and LATAM
✔Broker volume rankings, verification, and FM Intelligence Portal data
Speakers:
• Ramzi Ahmad, Director of Intelligence, Finance Magnates
• Sylwester Majewski, Head of Insights & Reporting Hub, Finance Magnates
• Philios Petrides, Data & Business Intelligence Consultant
If you work in brokerage, fintech, compliance, business development or market strategy, this session offers practical insights backed by verified industry data.
Access the FM Intelligence Portal at: https://datalab.financemagnates.com/
🔔 Subscribe to Finance Magnates for more webinars, interviews and market intelligence covering the global online trading industry.
#FinanceMagnates #FX #CFD #Fintech #Trading #Brokerage #MarketIntelligence #RegTech #Compliance #Forex
Where is the FX & CFD industry really heading in 2026?
In this free Finance Magnates Intelligence masterclass, industry experts explore the latest data shaping the global FX & CFD market, how regulation and regional demand influence expansion planning, and how brokerages benchmark performance across 265 firms on the FM Intelligence Portal.
In this session you'll learn:
✔ Where the FX/CFD industry is heading in H2 2026
✔ Why compliance should guide regional expansion decisions
✔ How internal performance compares when benchmarked against 265 brokers
✔ Regional demand shifts across Europe, APAC, and LATAM
✔Broker volume rankings, verification, and FM Intelligence Portal data
Speakers:
• Ramzi Ahmad, Director of Intelligence, Finance Magnates
• Sylwester Majewski, Head of Insights & Reporting Hub, Finance Magnates
• Philios Petrides, Data & Business Intelligence Consultant
If you work in brokerage, fintech, compliance, business development or market strategy, this session offers practical insights backed by verified industry data.
Access the FM Intelligence Portal at: https://datalab.financemagnates.com/
🔔 Subscribe to Finance Magnates for more webinars, interviews and market intelligence covering the global online trading industry.
#FinanceMagnates #FX #CFD #Fintech #Trading #Brokerage #MarketIntelligence #RegTech #Compliance #Forex
How Finance Leaders Adapt to Change | iFX EXPO
How Finance Leaders Adapt to Change | iFX EXPO
How Finance Leaders Adapt to Change | iFX EXPO
How Finance Leaders Adapt to Change | iFX EXPO
How Finance Leaders Adapt to Change | iFX EXPO
How Finance Leaders Adapt to Change | iFX EXPO
Markets never stop changing.
We asked finance executives for their number one success tip, and many came back to the same idea: adapt, stay informed and keep looking ahead.
Featuring executives from Shift Markets, Letknow Pay, Base Markets and SPAYZ.io.
#FinanceMagnates #Leadership #BusinessStrategy #Fintech #Shorts
Markets never stop changing.
We asked finance executives for their number one success tip, and many came back to the same idea: adapt, stay informed and keep looking ahead.
Featuring executives from Shift Markets, Letknow Pay, Base Markets and SPAYZ.io.
#FinanceMagnates #Leadership #BusinessStrategy #Fintech #Shorts
Markets never stop changing.
We asked finance executives for their number one success tip, and many came back to the same idea: adapt, stay informed and keep looking ahead.
Featuring executives from Shift Markets, Letknow Pay, Base Markets and SPAYZ.io.
#FinanceMagnates #Leadership #BusinessStrategy #Fintech #Shorts
Markets never stop changing.
We asked finance executives for their number one success tip, and many came back to the same idea: adapt, stay informed and keep looking ahead.
Featuring executives from Shift Markets, Letknow Pay, Base Markets and SPAYZ.io.
#FinanceMagnates #Leadership #BusinessStrategy #Fintech #Shorts
Markets never stop changing.
We asked finance executives for their number one success tip, and many came back to the same idea: adapt, stay informed and keep looking ahead.
Featuring executives from Shift Markets, Letknow Pay, Base Markets and SPAYZ.io.
#FinanceMagnates #Leadership #BusinessStrategy #Fintech #Shorts
Markets never stop changing.
We asked finance executives for their number one success tip, and many came back to the same idea: adapt, stay informed and keep looking ahead.
Featuring executives from Shift Markets, Letknow Pay, Base Markets and SPAYZ.io.
#FinanceMagnates #Leadership #BusinessStrategy #Fintech #Shorts
FM Daily Brief – 20 July 2026
FM Daily Brief – 20 July 2026
FM Daily Brief – 20 July 2026
FM Daily Brief – 20 July 2026
FM Daily Brief – 20 July 2026
FM Daily Brief – 20 July 2026
Today's Monday, the 20th of July 2026, and these are our main stories: two brokers surpass the two-trillion-dollar monthly trading volume mark, Asic posts a record year for civil penalties, and Jump Trading expands its prediction markets team.
Today's Monday, the 20th of July 2026, and these are our main stories: two brokers surpass the two-trillion-dollar monthly trading volume mark, Asic posts a record year for civil penalties, and Jump Trading expands its prediction markets team.
Today's Monday, the 20th of July 2026, and these are our main stories: two brokers surpass the two-trillion-dollar monthly trading volume mark, Asic posts a record year for civil penalties, and Jump Trading expands its prediction markets team.
Today's Monday, the 20th of July 2026, and these are our main stories: two brokers surpass the two-trillion-dollar monthly trading volume mark, Asic posts a record year for civil penalties, and Jump Trading expands its prediction markets team.
Today's Monday, the 20th of July 2026, and these are our main stories: two brokers surpass the two-trillion-dollar monthly trading volume mark, Asic posts a record year for civil penalties, and Jump Trading expands its prediction markets team.
Today's Monday, the 20th of July 2026, and these are our main stories: two brokers surpass the two-trillion-dollar monthly trading volume mark, Asic posts a record year for civil penalties, and Jump Trading expands its prediction markets team.
4 Finance Leaders Share Their Best Career Advice | iFX EXPO
4 Finance Leaders Share Their Best Career Advice | iFX EXPO
4 Finance Leaders Share Their Best Career Advice | iFX EXPO
4 Finance Leaders Share Their Best Career Advice | iFX EXPO
4 Finance Leaders Share Their Best Career Advice | iFX EXPO
4 Finance Leaders Share Their Best Career Advice | iFX EXPO
What advice has had the biggest impact on your career?
We asked four finance executives to share their number one success tip.
From perseverance to curiosity, their answers offer four different perspectives on building a successful career.
#FinanceMagnates #CareerAdvice #Leadership #Fintech #Shorts
What advice has had the biggest impact on your career?
We asked four finance executives to share their number one success tip.
From perseverance to curiosity, their answers offer four different perspectives on building a successful career.
#FinanceMagnates #CareerAdvice #Leadership #Fintech #Shorts
What advice has had the biggest impact on your career?
We asked four finance executives to share their number one success tip.
From perseverance to curiosity, their answers offer four different perspectives on building a successful career.
#FinanceMagnates #CareerAdvice #Leadership #Fintech #Shorts
What advice has had the biggest impact on your career?
We asked four finance executives to share their number one success tip.
From perseverance to curiosity, their answers offer four different perspectives on building a successful career.
#FinanceMagnates #CareerAdvice #Leadership #Fintech #Shorts
What advice has had the biggest impact on your career?
We asked four finance executives to share their number one success tip.
From perseverance to curiosity, their answers offer four different perspectives on building a successful career.
#FinanceMagnates #CareerAdvice #Leadership #Fintech #Shorts
What advice has had the biggest impact on your career?
We asked four finance executives to share their number one success tip.
From perseverance to curiosity, their answers offer four different perspectives on building a successful career.
#FinanceMagnates #CareerAdvice #Leadership #Fintech #Shorts