

Markets didn’t just get faster; they got busier. One screen won’t save you anymore. This piece breaks down what a full risk stack looks like on MT4/MT5/cTrader, why time is now your scarcest resource, and how teams turn many small signals into a few right actions—with proof.
If you run a brokerage today, you rarely fight one big fire. You juggle many small ones at once: a quote stream goes a little stale, a copy group wakes up, a swap change is late, margin calls spike after a macro print. None of this is exotic. The problem is time. You don’t get ten minutes to decide; some days you don’t get ten seconds.
The desks that stay calm don’t rely on point tools. They work with a risk stack—a few layers that see, decide, and act together. Fewer tabs. Fewer emails. Fewer “what just happened?” moments.
The job changed: not just faster—busier
24/5 meets 24/7. FX still runs five days, but crypto and synthetic products keep risk alive on weekends.
Event pile-ups. CPI/NFP and rate decisions now collide with dividends, swaps, and rollovers. Treat them as “edge cases,” and every week becomes an edge case.
More automation on the client side. Copy trading and group signals mean flow can switch on instantly, across many accounts.
Outage and geo-friction risk. Regional blocks and connectivity incidents don’t wait for quiet hours.
A quick look back (why time is the real risk)
Ten years ago, “one main dashboard + a solid bridge” could carry a retail broker. Today that creates lag debt—little gaps between seeing, deciding, and acting. It seems harmless until a Friday print hits, quotes desync for 90 seconds, and a cohort rides the gap. By Monday you’re doing forensics instead of planning growth.
What a full risk stack actually includes (five layers, plain English)
1. Unified visibility
One place to see the session right now: dealing exposure, A/B books, quotes health, live alerts, across all servers. No swivel-chair ops.
2. Signals that matter
Not vanity charts—actionable triggers. Typical set: Latency Arbitrage, Scalpers/HFT, Copy Cohorts (rings), Insiders, Churning, Rates Gaps/Desync, New Rates Absence, Large Volumes (order/account), Stop-out Abusers, Abnormal Volatility, Symbol-level unusual P&L, and so on.
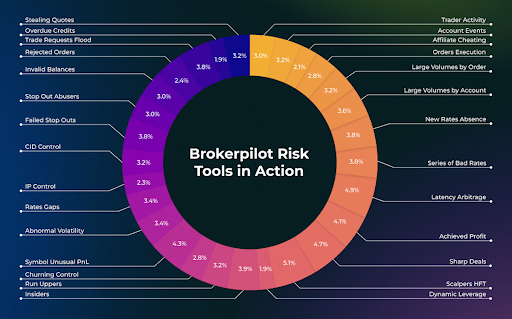
From our implementations across dozens of brokers, we usually see a few dozen active signals in production at any time; the top five drive most automated actions.
3. Automatic guardrails
Rules tied to signals: route A/B/Hybrid, hedge on accept, tighten leverage by equity tier, quarantine a symbol or group, and run corporate-action jobs (dividends, swaps, rollovers) with prepare → approve → log. Software handles the obvious moves; people look at exceptions.
4. Operations that don’t crack on busy days
A simple calendar so dividends/swaps/rollovers are boring and repeatable—exactly how you want them.
5. Evidence on tap
Clean post-trade reports: quote snapshots, order path (received → last look/accept → fill/reject), which trigger fired, what action ran, and timings. Five minutes to explain an outcome beats five emails.
Bonus: a quotes/ticks store (even feedable to a TradingView widget) helps show what the market looked like at decision time.
What goes wrong without a stack (three familiar stories)
1. The silent desync
Pricing looks fine on screen, but one LP drifts. A small cluster wins on stale quotes. With no automatic hedge, no cohort tag, and no event mode, P&L slips away in minutes; support spends hours explaining slippage.
2. The corporate-action stumble
A swap or dividend update is missed during a chaotic week. Each ticket is small—until there are many. A two-minute calendar job would have avoided the unwind.
3. The “speed is crime” mistake
In fear of toxic flow, you punish all fast traders. Short-term P&L improves; brand and volumes don’t. A better setup separates latency arbitrage from legitimate scalping and treats them differently.
Three drills you can steal this week
1) Macro-print drill (CPI/NFP)
−10 min: event mode ON → tighten leverage for low-equity tiers; widen LA thresholds on gold/indices.
During: suspected cohorts route conservatively; deep symbols hedge on accept (aim to send the hedge within ~100–150 ms—tune by symbol).
+30 min: event mode OFF; thresholds normalize; an after-action report compiles itself.
2) Outage/geo-block drill
Quotes health goes yellow; logins drop from one region. An alert pins it, a comms template goes out, temporary symbol limits apply, and hedge fails over to a backup LP. The report lands in the channel with timestamps and actions.
3) Ops reliability drill
Weekly 15-minute review of dividends/swaps/rollovers: who prepared, who approved, what ran, any diffs. Boring by design. Boring saves reputations.
What to measure (so you know it’s working)
Time to detect (TTD): seconds from issue to alert.
Time to action (TTA): milliseconds from accept to hedge/route/limit.
False-positive rate: how often rules penalize healthy flow.
Ops defect rate: missed/incorrect corporate actions per month.
Complaint cycle time: minutes to assemble evidence and close a ticket.
If these trends are the right way, P&L and reputation usually follow.
“Isn’t this just more tooling?”
No—fewer decisions at the right moment. A point tool gives you another tab and another alert. A stack removes obvious decisions by encoding them as rules. Dealers get their evening back; risk leads spend Monday on strategy, not archaeology.
A short, anonymized example
A mid-size broker running multiple servers moved from point tools to a stack approach. No buzzwords—just three changes:
1. symbol-specific LA thresholds on XAUUSD and US100,
2. equity-tier leverage around macro prints,
3. a short quarantine for two recurring copy cohorts.
Two weeks later: meaningfully lower exposure to toxic patterns and fewer “why did I get this fill?” threads. Same team. Fewer fires. Results vary; the method is repeatable.
Practical next steps (pick one)
Run an event-mode drill this Friday. Tighten leverage for low-equity tiers ten minutes before the print; relax thirty minutes after. Measure TTD/TTA.
Make a one-page “signal → action → SLA.” Four rows: Latency Arbitrage, Copy Cohorts, Rates Gaps/Desync, Large Volumes. Agree on who owns each action.
Put corporate actions on a calendar. Dividends, swaps, rollovers with prepare → approve → log. Small habit, big risk removed.







